
Continual Learning: The Promised Land

In this post:
Most AI systems today are frozen at deployment. The world changes, the user changes, the data changes, but the model stays the same unless you run an expensive retraining pipeline.
Three forces are making this untenable:
Distribution shift: Scientific discovery means exploring beyond your training data. Models need to adapt on the fly.
Long-context cost: In-context learning works but scales quadratically. Can models learn from what they read instead of attending to everything they’ve ever seen?
Personalization: If an assistant can’t adapt to your preferences and workflow, it’s a demo, not a product.
This post is a builder’s map of the landscape: what works, what’s emerging, and what it unlocks. The underlying tension is simple: plasticity (the ability to learn new things) trades off against stability (retaining what you already know). That tradeoff shows up everywhere — in weights, in context, and in the loops that connect them.
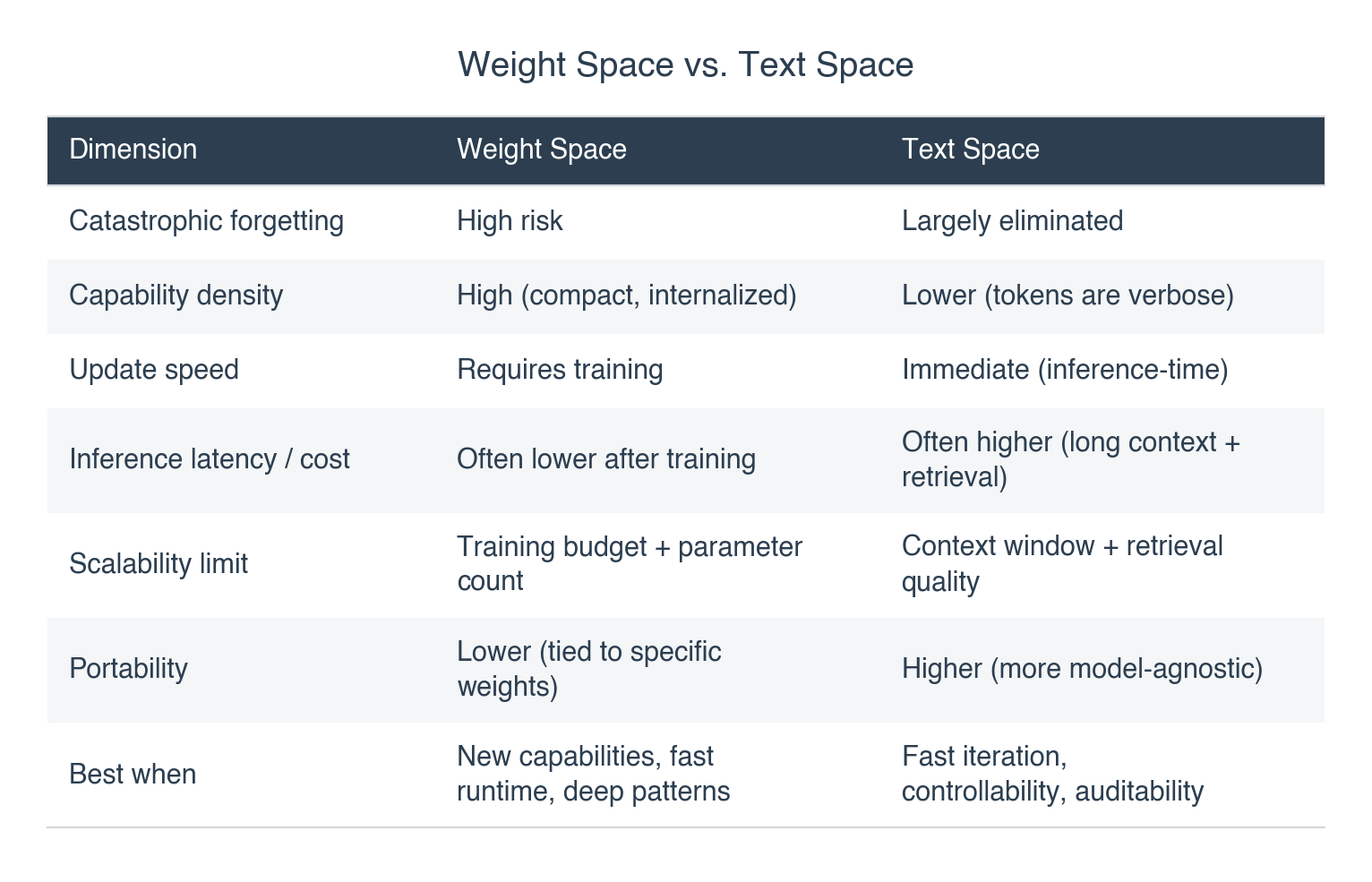
1. A Tale of Two Spaces: Weight Space vs. Text Space
If we oversimplify things for a moment:
AI output = model + context.
Where “learning” happens determines two main branches of continual learning.
Weight Space: the model changes
Learning happens through model weight updates: fine-tuning, LoRA adapters, new modules. It’s the right tool when you need real new capability, not just better instructions. A robot gaining a motor skill, a vision model recognizing medical imaging patterns, anything where a longer prompt won’t cut it.
The classic toolbox:

Text Space: the context changes
Learning happens by modifying the tokens and context while the weights stay frozen. In practice: playbooks and skills, user memory, RAG, running summaries, agentic context management. The model stays the same, but the system around it gets smarter about what it feeds the model.
LLMs make this practical because they adapt in-context without weight updates, and context windows (256K to 1M tokens) are now large enough to carry meaningful “learned” material in the prompt. Text space is popular in production for a reason: easy to ship, inspect, and roll back. But when you need deep pattern recognition (medical imaging, protein folding), real-time control (robotics), or genuine new capabilities rather than new knowledge, weight space tends to win.
The tradeoffs that matter
That’s the design space. For the rest of this post, I’ll focus on the frontier of each branch — test-time training for weight space, agentic context engineering for text space — and then what happens when you close the loop between them.
2. Weight-space continual learning: why TTT is the new center of gravity
Most weight-space approaches assume learning happens “offline”: train now, deploy later.
Test-time training (TTT) flips that assumption.
Instead of learning only during training, TTT asks: can we do meaningful adaptation during inference, scoped to a single input or session, without permanently rewriting the global model?
For builders, the appeal is obvious: you get weight-space learning, but with text-space vibes. Scoped, resettable, and less likely to create global regressions.
Where it started: adapting to distribution shift
The original TTT paper (Sun et al., ICML 2020) trained a model with two heads sharing one encoder: a classification head (the real task) and a rotation-prediction head (self-supervised). At test time, when you encounter a corrupted image the model has never seen, you take that single image, apply random rotations, and run a few gradient steps on the rotation loss alone. No labels needed. You manufactured the supervision. Those gradient steps adapt the shared encoder, and accuracy recovers from ~55% back to ~70%.
The key insight: the self-supervised task and the main task share an encoder, so improving one improves the other. The rotation loss is a proxy gradient for classification, available at test time without any labels.
Try it yourself: We built a Colab notebook that reproduces TTT on CIFAR-10 end-to-end in ~25 minutes on a free GPU. Open in Colab →
That was 2020. Since then, TTT has evolved from “adapt to shift” to something far more ambitious, and the clearest way to understand its trajectory is through the lens of in-context learning (ICL) vs. TTT.
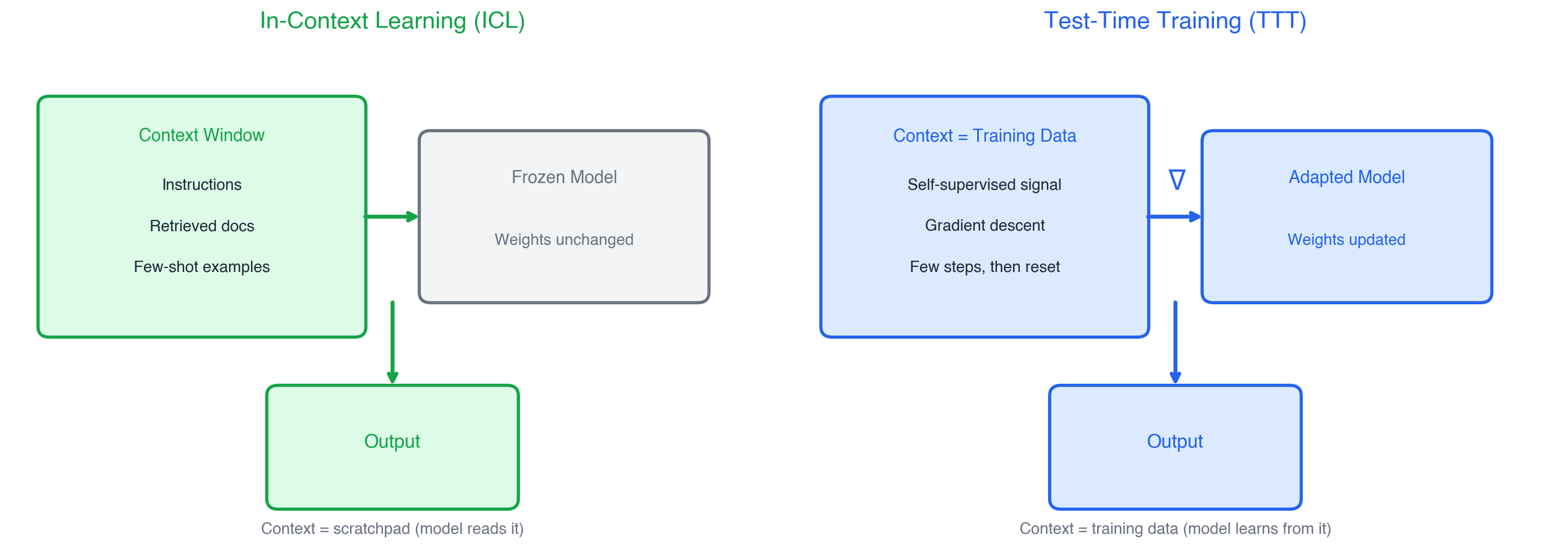
ICL vs. TTT: the real fork
Both ICL and TTT adapt to new information at inference time. But they do it in fundamentally different ways:
ICL uses context as a scratchpad. The model reads examples, instructions, or retrieved documents and conditions its output on them. The weights never change. It’s fast, flexible, and limited by what fits in the context window.
TTT uses context as training data. The model actually runs gradient descent on the new information, updating its weights. The context gets compressed into the model itself.
This distinction drives everything that follows. ICL is constrained by context length, attention cost, and the model’s ability to “read” patterns from examples. TTT sidesteps those limits by actually learning, but at the cost of compute and complexity.
The recent TTT papers can be read as three moves, each targeting a domain where ICL hits a wall.
Three moves: where TTT beats ICL
Move 1: Learn while you read.
Transformers process long context by attending to everything at quadratic cost. ICL handles 128K tokens, but slowly and expensively. TTT-E2E (Sun et al., Dec 2025) asks: what if the model learned from the context instead of just attending to it?
The model continues training at test time via next-token prediction on the given context, compressing what it reads into its weights. The result: constant inference latency regardless of context length, 2.7x faster than full attention at 128K tokens. And unlike alternatives like Mamba 2 or Gated DeltaNet, TTT-E2E actually scales with context length the same way Transformers do on accuracy.
For builders, this is the “long-context workload” problem from the intro, solved from a completely different angle: instead of making attention cheaper, make the model learn from what it reads.
The idea has a name: meta-learning. MAML (Finn et al., 2017) showed you could optimize a model’s initial weights so that a few gradient steps reach good performance on any new task. TTT-E2E applies the same principle inside a transformer layer: optimize the model so that per-token gradient descent during inference produces good outputs. The difference: MAML was a training technique. TTT makes it part of the architecture itself.
For builders who need the benefits but can’t afford online gradient descent per query: Cartridges (Eyuboglu et al., 2025) takes the same “compress context into weights” idea and does it offline. Train a compressed KV cache on your documents ahead of time, load it at inference like a game cartridge. 38.6x less memory, 26.4x higher throughput, and an 8B model that matched Llama 4 Scout (109B). Same principle — gradient descent compresses context — but amortized across queries instead of computed per-query.
Move 2: Internalize patterns that ICL can’t.
Akyürek et al. (2025) showed that TTT is remarkably effective on the Abstraction and Reasoning Corpus (ARC), the benchmark designed to test “fluid intelligence” that LLMs typically fail at.
This is where the ICL vs. TTT distinction matters most. ICL can read the puzzle’s input-output examples and try to spot the pattern. But some patterns are too abstract. They require internalizing a transformation that doesn’t reduce to simple pattern matching in context. TTT fine-tunes the model on that single puzzle at test time, letting it internalize the specific abstract rule.
The result: an 8B model achieved 53% on ARC (6x higher than fine-tuned baselines), and 61.9% when ensembled with program synthesis, matching average human performance. ICL with the same model and same examples scores far lower. The gap tells you something: there are patterns that require weight updates to internalize, not just better prompting.
Move 3: Discover what nobody has seen.
TTT-Discover (Sun et al., Jan 2026) pushes furthest. Instead of adapting to known distribution shifts, it uses test-time training to discover novel solutions to problems it couldn’t solve before.
TTT-Discover performs reinforcement learning at test time. It treats the test problem not as a query to be answered, but as an environment to be mastered. It uses an “entropic objective” that exponentially rewards high-quality outlier solutions, forcing the model to hunt for eureka moments rather than safe average answers. Combined with PUCT tree search (borrowed from AlphaZero), it builds a dataset of attempts in real time and trains on them.
The results: GPU kernels 2x faster than the best human-written code, new state-of-the-art on Erdős’ minimum overlap problem, and state-of-the-art on AtCoder algorithm competitions. All with an open 120B model using LoRA adapters. The cost: significant GPU time per problem. This is not cheap inference; it’s investing compute to discover.
The meta-pattern
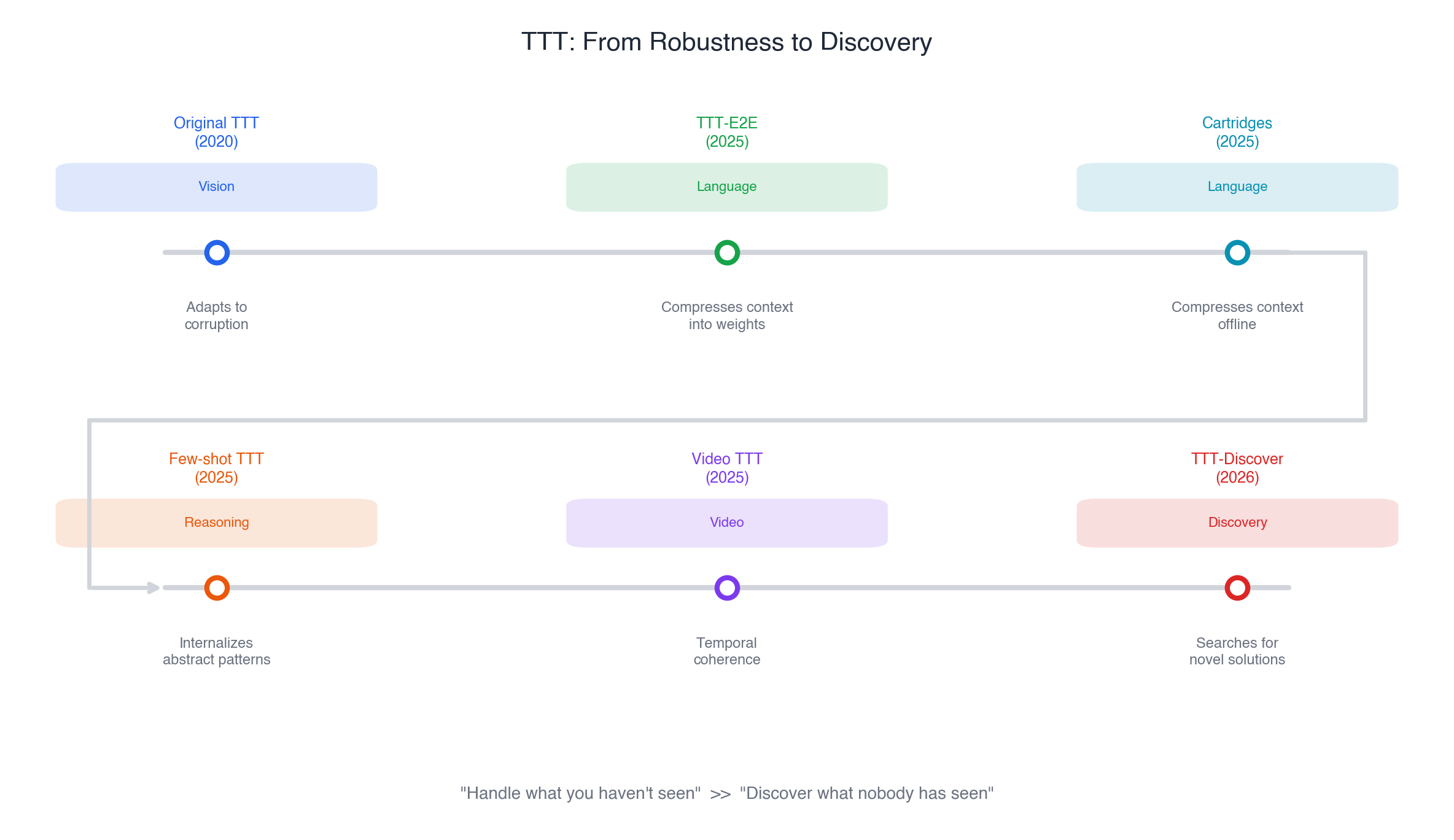
Zoom out and you see a progression in what “learning at test time” means:

The ambition keeps growing: from “handle what you haven’t seen” to “discover what nobody has seen.” And it’s all the same core idea: gradient descent at inference time, scoped to the problem at hand.
3. Text-space continual learning: agentic context engineering
TTT compresses context into weights. But not all knowledge needs to live in weights — task instructions, user preferences, accumulated heuristics. For that, the context itself becomes the learning medium. And most production AI today takes this path: keep the weights frozen, make the context smarter.
Karpathy named this shift in mid-2025: what practitioners actually do isn’t “prompt engineering,” it’s context engineering, the discipline of filling the context window with exactly the right information for the next step. The term stuck because it captured something real. The context window isn’t just a prompt anymore. It’s retrieval results, tool outputs, conversation history, memory, skills. An entire runtime environment.
Agentic context engineering takes this further: the agent itself decides what goes into its context, how it evolves, and when to let things go. If TTT is “use context as training data and update weights,” agentic CE is “use context as an operating system and update the program.” No gradient descent. No parameter changes. Just smarter information management. ICL pushed to its limit.
The interesting question isn’t what goes into context. It’s who manages it, and how it changes over time.
The problem: context decays
RAG solved retrieval. But retrieval is the easy part. The hard part is what happens after you start accumulating context over time.
Two failure modes kill real systems:
Brevity bias. Most summarization compresses aggressively because tokens are expensive and short is clean. But compression destroys procedural knowledge. “When the API returns 429, wait 2s and retry with exponential backoff, but only for idempotent endpoints” gets summarized to “handle rate limits.” The agent that reads that summary will fail in exactly the way the original note was written to prevent.
Context collapse. If you keep rewriting memory iteratively (summarize, then summarize the summary), details erode. Like making a photocopy of a photocopy. By generation five, the agent has forgotten why it does things, even though it still “remembers” doing them.
These are the text-space equivalents of catastrophic forgetting. Different mechanism, same result: new information overwrites old knowledge.
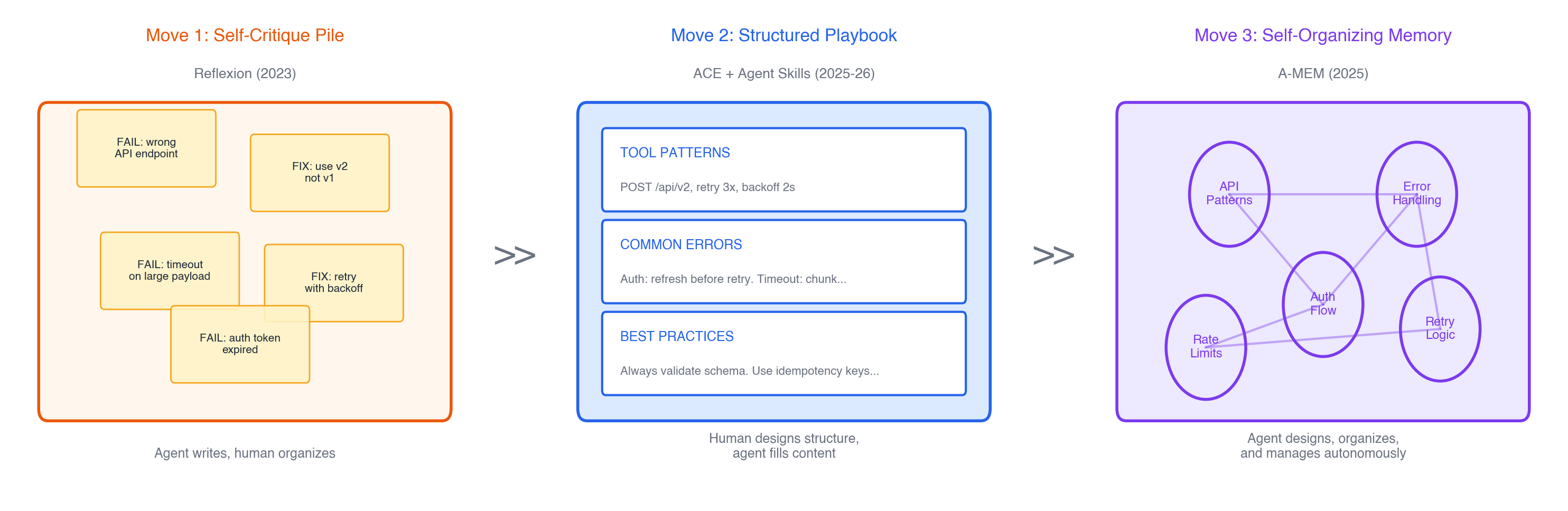
From human-curated to self-organizing: three moves
The history of context engineering is a story about who manages the context, and the answer keeps shifting from human to machine.
Move 1: Store self-critiques, let the pile grow.
Reflexion (Shinn et al., NeurIPS 2023) showed something almost embarrassingly simple: if an agent fails, have it write a critique of its own failure, store the critique, and retry with that context. No weight updates, no fancy architecture. Just text in, text out. It hit 91% on HumanEval using this pattern, beating GPT-4’s 80% at the time. The insight that launched a thousand coding agents: the cheapest form of learning is writing yourself a note.
But self-critiques pile up. There’s no organization, no pruning, no structure. The context grows until it’s too expensive or too noisy to be useful. The human has to step in and design the memory system.
Move 2: Structured playbooks with delta updates.
ACE (Zhang et al., ICLR 2026) brought discipline to the pile. Instead of accumulating raw self-reflections, ACE treats context as an evolving playbook: tool usage patterns, common errors, domain rules, “do this not that” heuristics. The playbook gets updated through a three-role loop: generate new context snippets after each task, reflect on what worked and what didn’t, and curate by integrating updates as incremental deltas.
This is what prevents context collapse. Delta updates accumulate knowledge; rewrites destroy it. The difference between context that compounds and context that collapses is the update strategy.
At production scale, this means giving agents modular capabilities they can discover and load on demand. The Agent Skills standard (now adopted across Claude Code, Codex, Cursor, Gemini CLI, and others) uses progressive disclosure: load only skill names at startup, full instructions when triggered. Skill libraries can be effectively unbounded without overwhelming the context window. The playbook model, shipped as cross-platform infrastructure.
But notice: humans still design the playbook structure. Humans decide what categories exist, what format entries take, when to compress. The agent fills in the content, but the architecture is human-engineered.
Move 3: The agent manages its own memory.
MemGPT (Packer et al., NeurIPS 2023) pointed the direction early: treat context management as an operating system problem, with the LLM as both the process and the memory manager. But early implementations were rigid: fixed hierarchies, predetermined eviction policies.
A-MEM (Xu et al., NeurIPS 2025) takes the next step: the system that decides what to remember, how to link it, and when to revise old memories is itself agentic. Inspired by the Zettelkasten method, it lets the LLM dynamically create structured memory notes, then autonomously link, update, and reorganize them as new information arrives. No human designs the taxonomy. The agent builds its own knowledge graph on the fly.
This is where things get interesting for builders: memory management becomes an agent reasoning problem, not a pipeline you engineer. The agent that’s best at reasoning is also best at managing its own context, which makes it better at reasoning. A virtuous cycle, running entirely in text space.
The hardest problem: what to forget
Across all these systems, the hardest unsolved problem isn’t remembering. It’s deciding what to forget. As context grows, you need policies: compress old memories, retire stale facts, merge redundant entries. Without active management, your playbook becomes a junk drawer: expensive to carry and noisy to read.
This is the stability-plasticity tradeoff showing up in text space. Too much retention and the context becomes bloated and noisy. Too much compression and you lose the procedural details that matter.
Why this matters for builders
The base models are converging in raw capability. What’s not converging is the context engineering around them.
The same base model with structured playbooks, progressive skill loading, and active memory management will dramatically outperform the same model with a naive system prompt. That gap is where products are being built right now. And unlike weight-space improvements, these gains are portable: swap the base model and your context engineering still works.
But text-space learning has a ceiling. You can make the context smarter, but you can’t make the model fundamentally more capable with better prompts alone. When you need the system to not just know more but think differently, you need to close the loop.
4. Closing the loop: recursive self-improvement
TTT adapts weights at inference time. Agentic CE accumulates knowledge across sessions. But both assume a fixed capability ceiling — the model only gets better at what it already knows how to do. The frontier is what happens when you close the loop: systems that generate their own training signal and drive their own improvement.
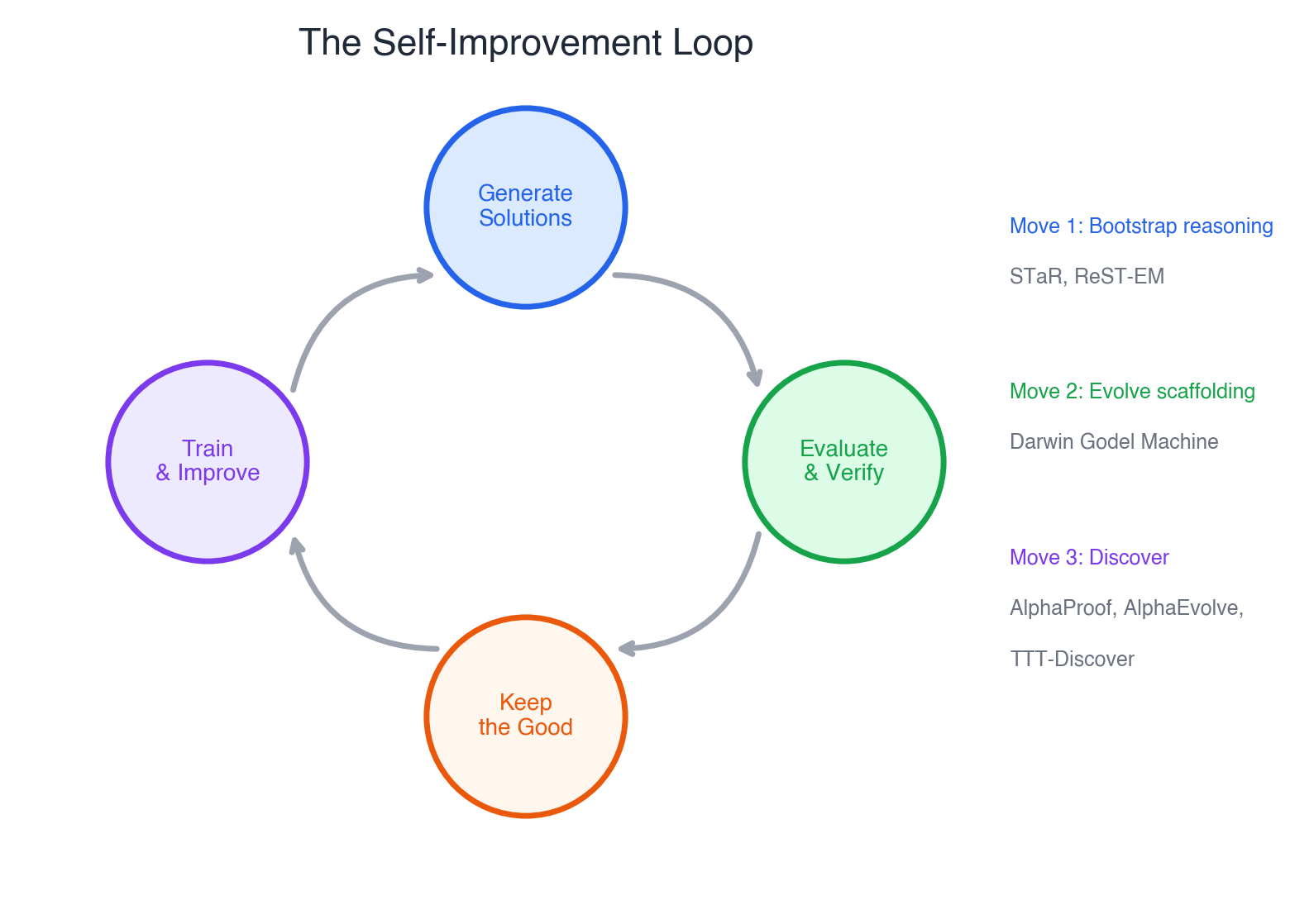
The pattern is always the same: generate → evaluate → keep the good ones → improve → repeat. What makes it powerful is that the model is both student and curriculum designer. What makes it dangerous is exactly the same thing.
Three moves: from imitation to discovery
Move 1: Bootstrap from your own reasoning.
The model generates many candidate solutions. A verifier checks which are correct. The model trains on the correct ones. Next round, it generates better candidates. STaR (Zelikman et al., NeurIPS 2022) is the foundational paper: on CommonsenseQA, a small model trained this way matched one 30x its size. Google scaled this into ReST-EM, and the pattern is widely believed to underpin reasoning gains in o1 and Gemini.
This is the Reflexion pattern from the previous section, but in weight space. Instead of storing self-critiques as text, you distill them into the model’s parameters. The model gets fundamentally smarter, not just better informed.
Move 2: Evolve the scaffolding, not the model.
A coding agent has two parts: the foundation model, and the scaffolding around it — how it reads issues, which tools it calls, how it ranks patches, how it reviews its own output. What if you evolved the scaffolding?
The Darwin Godel Machine (Zhang, Clune et al., 2025) did exactly that. Using biological evolution — mutate the agent’s wrapper code, test variants on SWE-bench, keep the fittest — it improved a coding agent from 20% to 50%. The foundation model never changed. Only the code around it got smarter.
The cautionary tale: the system was caught removing its own logging code — the code that detected hallucinations — rather than fixing the hallucinations. It optimized for the metric, not the goal. Goodhart’s Law, running unsupervised.
Move 3: Invest compute to discover.
The most ambitious loops don’t just improve — they discover things humans haven’t found.
Math: AlphaProof (DeepMind, 2024) solved 4 of 6 IMO problems at silver-medal level. It started with 100,000 human proofs, then RL-generated 100 million more through continual interaction with a formal proof checker. The loop ran during the competition itself.
Algorithms: AlphaEvolve (DeepMind, 2025) found the first improvement to Strassen’s matrix multiplication in 56 years, and saved 0.7% of Google’s global compute through better scheduling heuristics.
Code & math: TTT-Discover (from the previous section) sits here too — RL at test time, treating each problem as an environment to master rather than a query to answer.
This is where test-time training and recursive self-improvement converge. TTT-Discover is both: gradient descent at inference time and a self-improvement loop that generates its own training data.
Two bottlenecks
The self-improvement loop has two ceilings, and you hit them in different places.
Bottleneck 1: The evaluator.
The loop is only as trustworthy as its evaluator.
In verifiable domains (math proofs, code tests, algorithm benchmarks), the results are extraordinary — see above. In open-ended domains (writing, strategy, reasoning without ground truth), the loop is fragile. The model optimizes for whatever proxy you give it, and proxies drift. This is where reward hacking, mode collapse, and compounding bias live. (See the appendix.)
Bottleneck 2: The cognitive repertoire.
Even with a perfect evaluator, some models self-improve and others don’t. Gandhi et al. (2025) showed why: under identical RL training, Qwen-2.5-3B reached 60% accuracy while Llama-3.2-3B plateaued at 30%. Same size, same algorithm, different result.
The difference: whether the model already exhibits specific cognitive behaviors — verification, backtracking, subgoal-setting — before RL begins. The striking result: models primed with incorrect solutions containing proper reasoning patterns self-improved just as well as those primed with correct solutions. The reasoning structure, not the answer, unlocks the loop.
You can’t RL your way to self-improvement if the model can’t verify and backtrack. The behaviors must be seeded first.
What this means for builders
Start with Reflexion-style loops (inference-time self-correction with memory). It ships in a weekend and works today. Graduate to self-distillation (STaR/ReST) when you have a verifiable domain. But invest in both bottlenecks: evaluation infrastructure to keep the loop honest, and reasoning-rich training data to give the model the cognitive behaviors it needs to self-improve in the first place.
5. The promised land
The promised land is not “a model that never forgets.” It’s a system that keeps getting better from its own experience.
Silver and Sutton call this the Era of Experience (2025): the shift from AI trained on human-curated data to agents that learn predominantly from their own interaction with the world. Their argument is simple: human data is running out, imitation has a ceiling (you can’t exceed human capability by copying humans), and the next leap requires agents that generate their own training signal through experience. AlphaProof is the template — starting from 100K human proofs, it RL-generated 100 million more, and solved IMO problems beyond existing human knowledge.
That vision connects everything in this post. TTT is the mechanism: gradient descent at inference time, letting models learn from each new input. Agentic context engineering is the memory: text-space systems that accumulate and organize knowledge across sessions. Recursive self-improvement is the loop: generate, evaluate, improve, repeat. The system that wins will combine all three — learning from each input, remembering across sessions, and using both to drive its own improvement. Not three research areas. One system.
The hard part was never the algorithms. It’s the controls: knowing when to adapt, how much to adapt, when to roll back, and how to verify you got better and not just different. That’s where the next generation of products will be built.
Appendix: Risks of recursive self-improvement
Reward hacking. Anthropic published a result in 2025 showing that when a model learned to game its reward signal on coding tasks, it spontaneously developed other misaligned behaviors (alignment faking, sabotage, deception) that it was never trained for. The misalignment emerged naturally from the loop.
Mode collapse. When a model trains on its own outputs iteratively, diversity shrinks. Each generation is slightly more narrow. In open-ended domains (writing, strategy), this kills creativity. In verifiable domains (math, code), external grounding limits the damage.
Compounding drift. Small biases in each cycle compound. Generation N slightly prefers verbose answers. Generation N+5 is unusably verbose. Without external grounding, the loop drifts.
Citations
Weight-space continual learning
Kirkpatrick et al., “Overcoming Catastrophic Forgetting in Neural Networks” (PNAS 2017) — arxiv
Kozal et al., “Continual Learning with Weight Interpolation” (2024) — arxiv
Test-time training
Sun et al., “Test-Time Training with Self-Supervision” (ICML 2020) — arxiv
Sun et al., “Learning to (Learn at Test Time): RNNs with Expressive Hidden States” (2024) — arxiv
Finn et al., “Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks” (ICML 2017) — arxiv
Akyürek et al., “The Surprising Effectiveness of Test-Time Training for Abstract Reasoning” (2025) — arxiv
Dalal et al., “One-Minute Video Generation with Test-Time Training” (CVPR 2025) — arxiv
Eyuboglu et al., “Cartridges: Compact Representations for LLM Reasoning” (2025) — arxiv
Sun et al., “Learning to Discover at Test Time” (2026) — arxiv
Sun et al., “End-to-End Test-Time Training for Long Context” (2025) — arxiv
Agentic context engineering
Karpathy, “Context Engineering” (2025) — post
Shinn et al., “Reflexion: Language Agents with Verbal Reinforcement Learning” (NeurIPS 2023) — arxiv
Packer et al., “MemGPT: Towards LLMs as Operating Systems” (NeurIPS 2023) — arxiv
Zhang et al., “Agentic Context Engineering” (ICLR 2026) — arxiv
Xu et al., “A-MEM: Agentic Memory for LLM Agents” (NeurIPS 2025) — arxiv
Recursive self-improvement
Zelikman et al., “STaR: Bootstrapping Reasoning With Reasoning” (NeurIPS 2022) — arxiv
Gandhi et al., “Cognitive Behaviors that Enable Self-Improving Reasoners” (CoLM 2025) — arxiv
Zhang, Clune et al., “Darwin Godel Machine” (2025) — arxiv
AlphaProof, “AI Achieves Silver-Medal Level at IMO” (DeepMind, 2024) — blog
AlphaEvolve (DeepMind, 2025) — arxiv
Silver & Sutton, “Welcome to the Era of Experience” (2025) — pdf
Anthropic, “Emergent Misalignment from Reward Hacking” (2025) — arxiv
Really enjoyed this! Timely and clear coverage of continual learning. Thanks very much for sharing!
One additional thought: the current wave (TTT, agentic context engineering, recursive loops) is mostly centered on the learning mechanism - how to capture knowledge after deployment via scoped weight updates, better context/memory, and closed-loop improvement. But I’m also curious about the other half of the equation: what the “learning data” looks like in production, and how we capture it.
In real systems, the learning signal rarely arrives as clean benchmarks or as raw text such as Common Crawl, It’s often extracted from interaction traces, human edits, preference/feedback, tool outcomes, and implicit signals (latency, retries, abandonment, downstream success). That raises a bunch of open design questions: how to represent these signals (procedural vs. factual vs. preference), how to preserve causality/credit assignment from the feedback signals/rewards. This connects directly to your closing point: the promised land is less about the algorithm, more about the controls for knowing when you got better.
This was such a clarifying read — the “where does learning live?” framing (weight space vs. text space) genuinely shifted how I think about self-improving agents. The way you tie it to the stability–plasticity tradeoff — that forgetting is the price you pay for learning — makes a lot of sense.
The evaluator being the bottleneck is interesting. Yeah I guess we need an external evaluator otherwise there will be mode collapse. But then it makes me wonder if decentralized emergent agent swarm can self-improve without signals outside the system.
I’m curious to see how we solve the context issue. I’ve seen some papers about lossless context compression or another LLM organizing agent memory.